I have mixed feelings about the current post. For the specific problem at hand, I had intended to develop a series of solutions, the one represented here being just the first one, soon to be replaced by a better one. However, for reasons I am going to go into later, I settled for this one, for the time being.
The domain of discourse is: workflow specifications, and how to verify them. Wide and under-specified enough to make for an interesting problem. My first thought for a quick-and-dirty solution, which would give some immediate results until the more elaborate ones brewed, was to develop a program to evaluate some pertinent constraints on possible paths through the workflow, and my choice for the language to use was Prolog. The reason is the painless facilities it has for state-space exploration: backtracking, incremental elaboration of data and pattern-matching through unification and conciseness. Plus, back in the ol’ days, I considered myself a decent Prolog programmer. Now, it could be debated whether tag “Esoteric” is really suitable for Prolog . After all, it has been around for more than forty years, and most universities teach it. However, it remains impenetrable for the uninitiated, and I don’t think many people actually learn it, even if they are taught about it.
For reasons unknown I had to start with Visual Prolog. Probably because I had avoided Turbo Prolog when it came out and I never had more than a casual glance at Mercury, Oz and other multi-paradigm languages. That phase lasted the better part of two days, then I got fed up with the nagging message at startup and I went back to the less flashy SWI Prolog.To make a long story short, what I did was the following. My program loops through all of our workflows, reads them as Prolog facts and then runs the actual verification code on each one. The focus of this post is the actual verification code running on the graphs which encode the workflows.
Each verification rule looks for counter-examples of the property it encodes, which are paths through the graph. It consists of the following components: a selector of initial nodes, a filter that limits the edges taken from each node, and a selector of final nodes. Other than limiting the search space with the aid for those components, exploration is exhaustive, since we’re looking for counterexamples.
For example, the following clauses of the filter predicate for a particular rule, encode some workflow conditions on having or not having passed through a prior workflow step (and the lack of syntax highlighting for Prolog from WordPress certainly justifies the “Esoteric” tag).
allowed_arc(N,V) :- stepcond(N,through(I)), member(I,V), !. allowed_arc(N,V) :- stepcond(N,not_through(I)), member(I,V), !, fail.
As you can see, the filtering predicate takes as parameters the node to go to, and the sequence of previously visited nodes. The filtering predicated is called by predicate possible_path, which computes the path.
possible_next(V, Pr, X, Y) :- stepact(X,goto(Y)), apply(Pr,[Y,V]). possible_next(V, Pr, X, Y) :- stepcond(Y,input(_)), X \= Y, apply(Pr,[Y,V]). possible_path(V,_,X,X,P) :- reverse(V,P). possible_path(V, Pr, X, Z, P) :- possible_next(V,Pr,X,Y), possible_path([Y|V],Pr,Y,Z,P).
Evaluating the rule is done with the help of findall.
findall( P, (stepact(F,soi), possible_path([F],allowed_arc,F,Z,P), length(P,L), L > 1, stepact(Z,soi)), X4)
It needs a second look, so let me break it up.
stepact(F,soi) Start from every action matching the particular fact pattern.
possible_path([F],allowed_arc,F,Z,P) Enumerate all possible paths using the particular filter.
length(P,L), L > 1, stepact(Z,soi) Stop for all paths of length > 1 whose final node matches the particular fact pattern.
A brute-force solution, but managed to sniff out several potential problems in the workflows and has room to grow with new rules. Why did I say that its only purpose was to pave the way for more elaborate solutions?
My hope was to use formal verification methods, and I had every reason to be hopeful because I had multiple candidates to try.
The first one was UPPAAL, a tool which allows one to specify timed automata, simulate them and verify invariants expressed in CTL. Sounds cool, doesn’t it?

The problem is, encoding your system in this way is not an easy task, and probably not something that could be done by translating a workflow specification automatically. And people who used it independently had trouble adapting the tool to their problem and ended up actually playing to the strengths of the tool. It’s not out the question, but it needs a lot of time and dedication, and it is not a short-term study.
My other hope was to express the path constraints using LTL, instead of the unstructured way I was using. Which necessitated a lot of research to find how LTL can be verified and what tools there are to aid one in this endeavor. It turns out there are, and some of them have been also put online for people to test! Try out LTL2BA and SPOT. And, if you persevere through various tortures imposed on you by the intricacies of cross-platform C/C++ builds, you can actually find yourself with real singing and dancing LTL2BA and SPOT executables that you can invoke. Best of all, they can both be made to output (semi-?) standard LBT format. To give you an idea, the formula G p3 | (F p0 & F p1) results in the following Büchi automaton (yes, that’s what it’s called) which can be used to verify it at run-time.

This was something I’ve been considering for Pandamator, as well, to express constraints for whole object lifetimes. As I found out, it was not a novel idea, but maybe I’d have the honor of implementing it first in an accessible way. It would need some elaborate machinery: abstract away all logic that is not LTL (formulas to translate have simple propositional variables), invoke an external program, read back the automaton and fill back in the actual logic conditions. That would replace my hodge-podge filters and selectors with something having real logical backing. The problem is, trying to write the darned LTL constraints proved to be not evident!
For example, how would the following be written? After action p0, action p2 cannot appear unless condition p1 appears between them. My guess would be p0 -> X G ((!p1 & !p2) U (p1 U p2)). However, the automaton does not seem to be suitable.
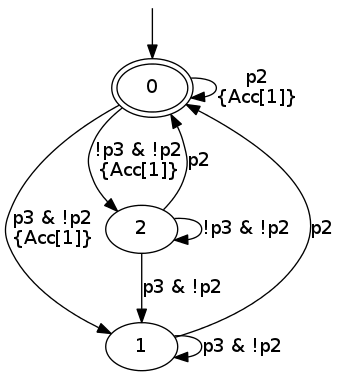
This is my current situation… Maybe an intermediate solution would be to formulate an automaton directly, and use it as the specification of the constraint.
I won’t pretend I know the answer. I’m in the dark, but I’m determined to see this through. And, in the meantime, my lowly Prolog program can actually chug along and produce useful results…

Pingback: Constraints on workflow paths, part 2 | dsouflis
Pingback: New table constraint planned for Pandamator (Constraints on workflow paths, part 3) | dsouflis
Pingback: LtlChecker, part 2 | dsouflis